Introduction
Youboox is a young startup offering a subscription to ebooks. Over the time we discovered the challenges of processing long and complex background jobs on Heroku, we’ll see how we solved them by moving our book pour processing infrastructure to EC2.
Why we started with Heroku :
Late 2011 when we started to write the first lines of code for Youboox, we had very limited ressources and a lot of things to do. The beta service included :
- 1 Rails app for publisher to upload their books
- 1 iPad app
- 1 json API in rails
At that time we had 2 priorities : signing deal with publishers and growing our user base.
Our technical choices aimed at delivering value as fast as possible to users and publishers. We were focused on development rather than managing infrastructure, so Heroku was a perfect fit in this situation, it was great to get up and running fast without ever having to ssh to a server. If i had to do it again i would definitely go for Heroku.
Our context
When we receive a new book we start a backround job that will :
- Compress the book (ex : extracting image, compressing them, etc)
- Slice the book into several smaller files, so we can send only pages corresponding to the current position of the user in the book
- Crypt the file to apply our custom DRM
These jobs take between a few minutes to almost an hour for the larger books (some of the files we receive are over 100 Mo)
Our book processing infrastructure :
At the betinning of 2012 after a few months of development we released our beta, this is how our background job infrastructure looked like :
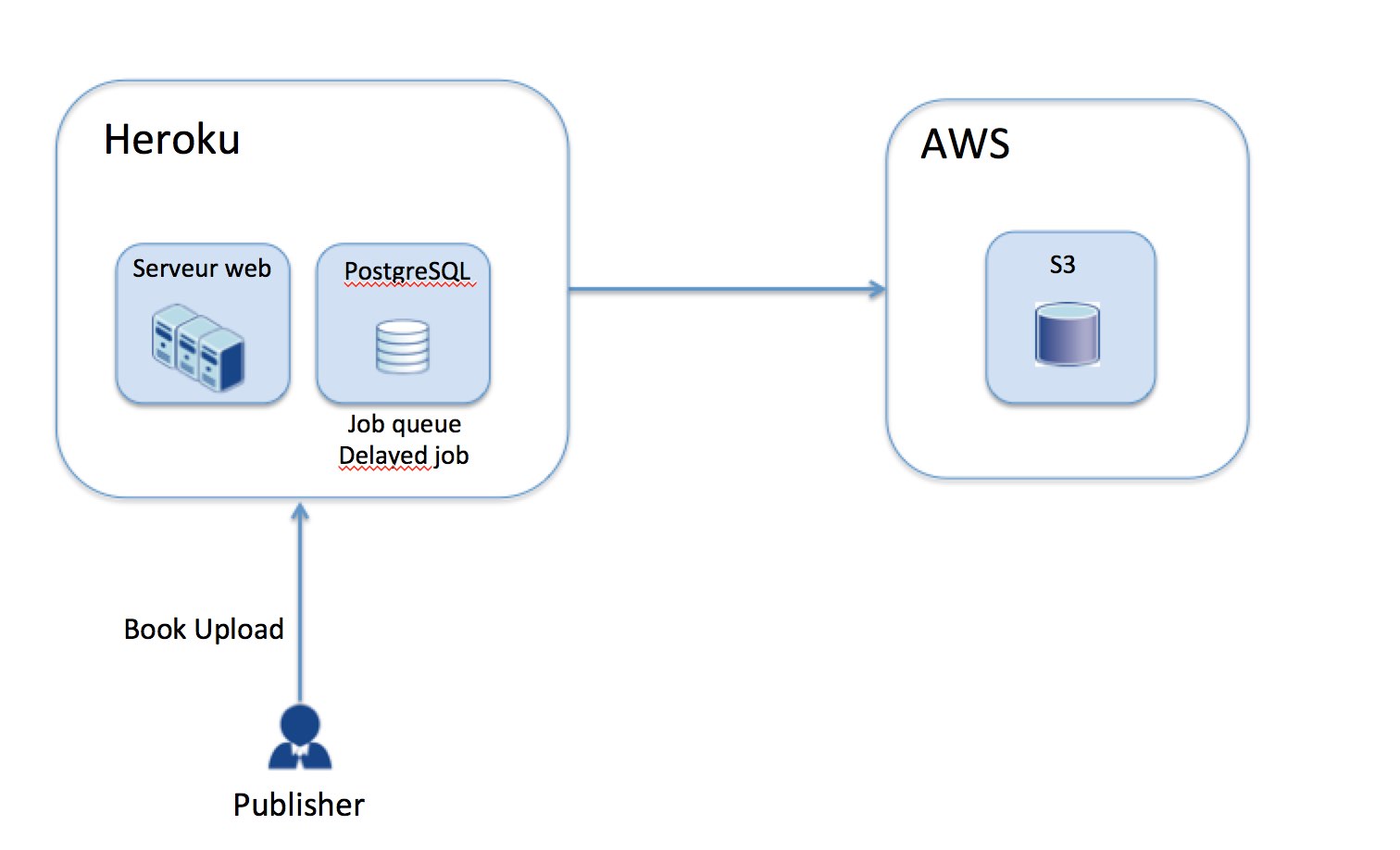
It was fairly simple : A publisher would upload a book on our web app It started a background job, that includes the following steps :
- Compressing
- Slicing
- crypting
When the job was done the files were stored on AWS S3
Monitoring problems :
This simple approach roughly worked. But we soon discovered it had several drawbacks :
The book industry is very different from the music or film industry, the standard for digital books is the epub format, problem is every publisher is doing it their own way.
Everytime we would sign a new publisher we received a different epub format…
As you can imagine this creates a lot of unexpected behavior during the processing. Heroku makes it really hard to investigate this kind of error :
The platform was not designed to easily SSH on a worker and inspect what process is using too much ressources. Heroku also kills a lot of worker, which is ok when you have a lot of short jobs, but becomes a problem when you are running few long running jobs :
- worker are restarted every 24h
- When heroku detects a problem on a worker (high load, etc) it tends to kill it
- when RAM is getting over 500% of your quota it gets killed
We couldn’t easily scale the number of worker according to the number of books in the queue. When we receive a batch of new books we would starts more worker, and then manually shut them down. This caused a lot wasted processing power (and money..)
Note: At that time we tried Hirefire which was at its early stage and not production ready. Service such as Adeptscale didn’t exist at that time.
We were also constrained by the binaries that were installed by default on Heroku instances, most of the time older version. It was very frustrating to face bugs in Imagemagick that had already been fixed and being unable to update it..
But despite these problems it was working.
What really made us switch to EC2 was the migration from Bamboo et Cedar.
We were heavily relying on PDFTK to process PDF files, and this lib was simply removed from Cedar. We started to look how to create a custom buildpack for Cedar, but it just felt like we were really using a platform that didn’t suit our needs any more.
At this point we decided to extract all code related to background processing into a seperate ruby app and host it on EC2. It would allow us to install libs missing on the Cedar stack and at the same time solve the other issues we already had :
- monitoring
- auto scaling
- debugging
Note: We were already using New relic which is an amazing tool for high level infrastructure monitoring. We had a general overview of the global health of our platform both with performance monitoring and alarming. But New relic is not designed to monitor process so it didn’t help to debug our background jobs : we needed to know what specific process was taking to much ram, when the local disk was full, etc
Our current infratructure for background job processing :
When we moved to EC2 our main concern was the deployment process. Coming from Heroku where everything is automated from day one, we were worried it would be long and painfull to get to the same level of automation and robustness.
It turned out to be a lot simplier than we thought by using an AWS service called Opswork :
AWS OpsWorks is an application management service that makes it easy to deploy and operate applications of all shapes and sizes. You can define the application’s architecture and the specification of each component including package installation, software configuration and resources such as storage
It allows you to describe a stack layer : OS and packages, using a set of Chef recipes. Then describe an app layer (database migration, etc) Once it’s setup you can add new instances with one click. You can deploy an update of your app in one click as well.
The nice thing is that you can setup auto-scaling really easily from the opswork interface, it will take care of all the details for you (creating an auto-scaling group and config, cloudwatch alarms, etc), you just need to set either a CPU load based treshold (start new instances when existing ones are overloaded), or a time based treshold (start instances at given time of the day) For more info about Opswork see LINK TO DOC
When this new book processing application was up and running, our new infrastructure looked like this :
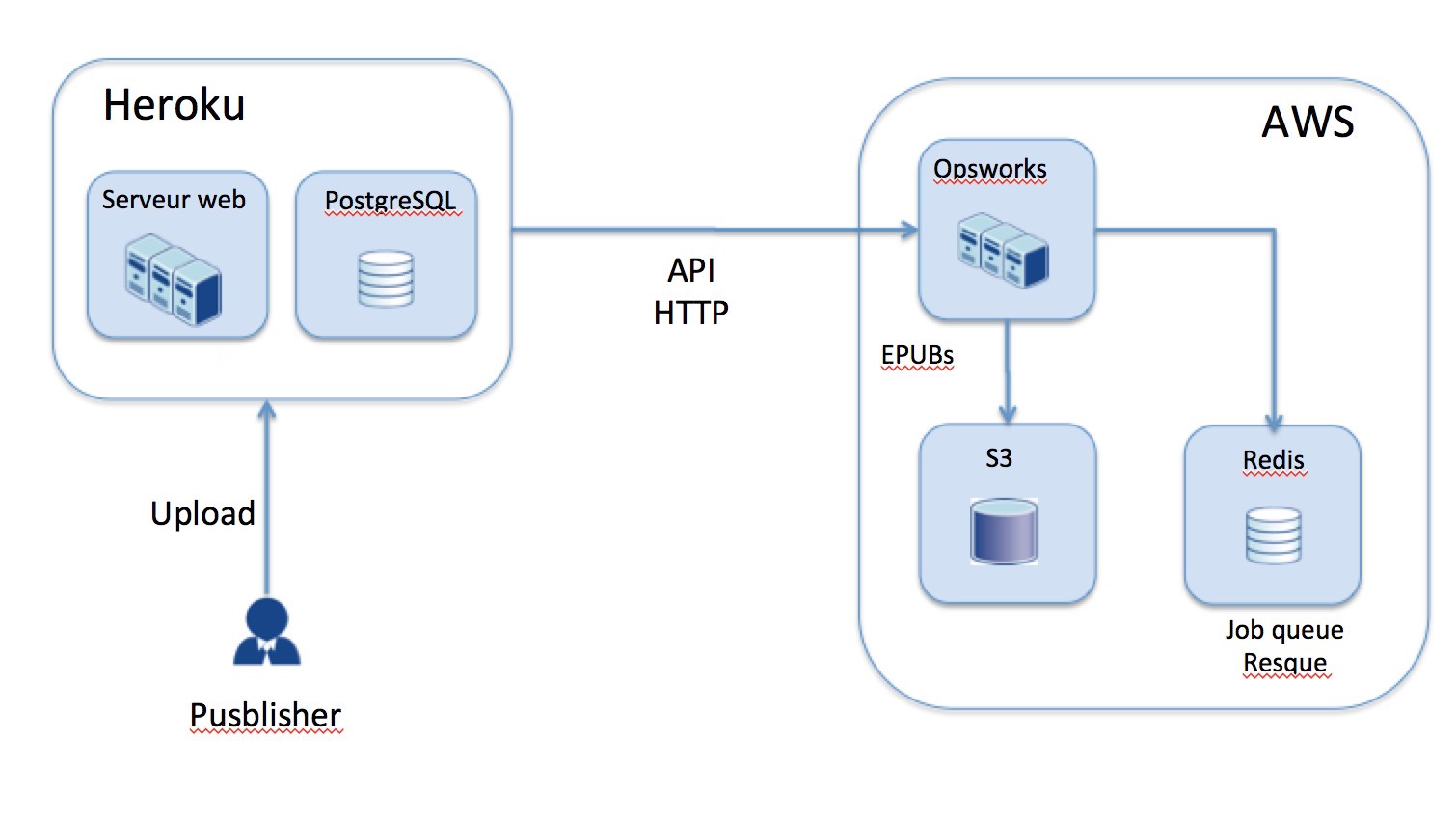
Now when a publisher uploads a book, it sends an http request to our book processing app.
This app then adds a background job to Resque.
When the job processing starts, CPU load gets over the treshold and Opswork starts another instances.
When the instance is setup and the app deployed it pulls another job in resque, CPU load of thiz new instance reaches treshold and so on.
When there is no more jobs to process CPU load goes below the treshold and Opswork shuts down instances.
When the book is processed, the files are still stored on S3 and we send an http request is sent back to our API on heroku to inform that the book is ready to be streamed to clients.
Now when something goes wrong we can SSH to instances, inspects processes and view logs for this specific instance.
It also allowed us to do things that would have been very complex on Heroku, such as computing the number of pages of a book : we render the book in a headless browser with Phantom.js and get the height of the book in pixels.
Other benefits
Moving to EC2 also helped us resolve some other issues we were having with background jobs. To run a rake task on our production environment Heroku uses what they call one-off dynos
We use rake tasks for such things as data migration and computing analytics.
As our database was getting bigger these jobs started to take longer to process. We started to face several issues : Heroku would randomly kill some process after a few hours, with no obvious reason (RAM quota ?) Even when the job wasn’t killed, it began to be difficult to run these jobs from a local developer shell, and if we run the process as a background job, logs where lost with other production logs
We now use Jenkins on a EC2 instance to schedule jobs such as sending analytics reports, or nightly batch computing. Using Jenkins provides lots of cool tools out of the box :
- History of job processing time
- Separate logs with history
- Mails alert when job crashes
Conclusion :
Fast forward to 2014, moving to EC2 has been a huge improvement to our book processing workflow. We stayed on Heroku for all client facing apps like the publisher web access and our JSON API.
We are still very happy to delegate our most critical infrastructure and let Heroku engineers monitor the low level aspects of our infrastructure. The rails API and our user website have fairly standard needs and Heroku, though not perfect, is quite good at solving this kind of use case.
Concerning background jobs we also still use Heroku for things like sending mail, indexing objects on our search engine, etc These jobs are short lived, and are easy to monitor : if anything goes wrong a crash report is enough to understand what went wrong.
On the other hand the book processing app solves use cases very specific to our business. It deals with complex long running jobs, with dependencies to packages not available on Heroku by default.
For these jobs we now monitor and fix issues ourself, which, as we’ve seen, is actually what we wanted : To have full control over the more complex components of our system. These complex components were also good candidates for migration to EC2 as they are less critical for business in case of failure : For example if an analytics job or some book processing fails during the week end, we can wait a couple of days to fix it (And this is the worst case scenario)
That’s it !
have you already moved from Heroku to EC2 ? Are you considering to do it ? Would you have done things differently ? If so leave a comment.